
版权声明与出品方简介
版权所有 © 2025 AI琴报局
本报告由「AI琴报局」独家出品,保留所有权利。
允许在保留出品方信息及联系方式的前提下免费传阅与分享。未经书面授权,严禁对本报告进行修改、删减或用于商业出售。
【我们为您提供什么?】
本报告仅是我们服务能力的冰山一角。我们致力于连接 AI 生态中的核心角色:
面向 CTO 与技术决策者 ——「省心省力的避坑指南」
我们深知技术选型的压力。我们为您提供客观的测评与咨询,助您在复杂的 AI 版图中快速找到最适合的路径,规避潜在风险,让每一项决策都稳健而高效。面向开发者与技术专家 ——「被看见的展示平台」
我们致力于成为连接您与企业需求的桥梁。在这里,您的创新解决方案将与真实的商业场景相遇,释放最大价值。
【联系与合作】
无论您是寻求 AI 解决方案的企业,还是拥有出色技术的开发者,欢迎与我们深度交流。
深度交流 / 需求对接 / 商务合作:
请添加主理人微信:AAIQIN2046关注我们的频道(获取最新落地案例与行业洞察):
微信视频号: AI琴报局 (ID: sphGnUUstHSbwzp)
抖音: AI琴报局 (抖音号: 81736079492)
YouTube: https://www.youtube.com/@AI%E7%90%B4%E6%8A%A5%E5%B1%80/shorts
第1章 核心摘要
1.1 测评综述:从“炫技”到“落地”的残酷大考
2025 年,AI 视频生成技术正式跨越了“娱乐试玩”阶段,迈向商业实质性生产周期。本报告针对全球 5 款代表性工具(Google Veo, Runway, PixVerse, 可灵AI, 即梦AI)进行了 17 项高压测试。结果显示,市场并未出现价格战,反而形成了明显的“算力阶层固化”。
1.2 关键发现
画质与成本的“降维打击”: Google Veo 以最高的 MOS 评分(3.96)和最低的单次成本(1.44元),确立了 2025 年的行业标杆。其 Fast 模式成功实现了“电影级画质与白菜价成本”的共存。
定价模式的“两极分化”: 市场呈现哑铃型结构。Runway 与 可灵 AI 单次生成成本均突破 12元人民币,且存在“失败扣费”等隐形税,商业试错门槛极高。
本土化与全球化的错位: Google Veo 意外在中文语义理解上夺冠;可灵 AI 凭借对中国文化(古风、成语)的精准把控,依然是国内短剧市场的不可替代者;PixVerse 则因中文理解能力极弱(需英文指令)而主要服务于专业后期市场。
“半成品”交付痛点: 行业距离“一键成片”仍有距离。即梦 AI 无声、PixVerse 逻辑突变等问题普遍存在,“组合式工作流”(如 Veo生成 + PixVerse修图)是当前唯一解法。
1.3 核心结论
2025 年不是单一工具的胜利,而是“算力性价比”与“工作流整合”的博弈。未来的赢家将是那些能灵活组合 Google 的廉价算力、可灵的本土语境以及 PixVerse 精细控制能力的创作者。
第2章 测评背景与范围
2.1 测评背景与目的
2.1.1 行业现状:从“技术狂欢”走向“生产力变革”
技术成熟度跨越:视频生成模型已突破了早期的“几秒动图”限制,Google Veo、Runway Gen-3 等头部模型在长视频生成(10秒+)、4K超高清分辨率、以及物理规律模拟(如流体、光影反射)上取得了决定性进展。
竞争格局重塑:市场不再由硅谷巨头独占。以可灵AI、即梦AI为代表的中国本土模型强势崛起,不仅在中文语义理解上占据天然优势,更在生成质量和响应速度上与国际顶尖模型分庭抗礼,形成了“东西方技术并跑”的新格局。
应用场景深化:用户的核心诉求已从单纯的“尝鲜试玩”转向影视预演(Pre-vis)、短视频营销、电商素材制作等实质性生产环节。然而,随着技术的普及,市场上涌现出数十款工具,功能同质化与宣传夸大化现象并存。
2.1.2 测评目的
尽管各家厂商的官方演示(Showcase)效果惊艳,但在实际应用中,普通用户往往面临着巨大的“预期效果与实际表现”落差。本报告旨在解决以下核心痛点:
祛除信息噪音: 许多工具在特定提示词下表现优异,但在面对复杂的中文指令或特定行业需求时往往“幻觉”频出。我们需要通过标准化的测试,还原工具的真实能力边界。
量化投入产出比: 2025年的AI工具普遍采用了复杂的订阅或积分计费制。对于企业和个人创作者而言,不仅要看“能不能做”,更要看“做一次多少钱”以及“要抽卡多少次才能成功”。本报告引入独特的“单位画质成本”算法,为不同预算的用户提供精准的选型依据。
聚焦中文语境: 鉴于大多数测评基于英文环境,本报告特意采用全中文提示词进行压力测试,旨在为中国用户筛选出真正“听得懂、做得好”的AI视频生产力工具。
2.2 测评对象与范围
2.2.1 测评对象清单
本报告甄选了当前全球市场(含中国大陆地区)最具代表性、用户基数最大且技术架构领先的 5 款 AI 视频生成工具。这些工具代表了 2025 年该领域的“第一梯队”水平,涵盖了从科技巨头自研到底层模型创业公司的多元生态。
国际阵营:
Google Veo:Google DeepMind 推出的旗舰级视频生成模型。作为科技巨头的“技术旗舰产品”之作,Veo 代表了当前行业在物理模拟和高保真画质上的技术天花板。
Runway:AI 视频领域的“老牌”先驱,深受专业影视创作者喜爱。其工具链完善,常被视为创意工作流的标准配置。
PixVerse:在全球范围内迅速崛起的黑马平台,以其独特的社区生态和对特定风格(如二次元、CG风)的优秀兼容性著称。
国内阵营(本土化主力):
可灵 AI (Kling):快手团队研发的视频生成大模型。凭借对真实物理世界的优秀模拟能力和对中文语境的深度适配,成为国内用户的首选工具之一。
即梦 AI (Jimeng):字节跳动旗下的创意工具平台。依托其强大的图像审美积累,即梦在画面构图、色彩美学及短视频应用场景上具有显著优势。
2.2.2 测评版本与配置说明
为确保横向对比的科学性与公平性,针对 AI 模型迭代快、版本多的特性,本测评严格执行以下版本控制与参数标准化原则:
模型版本选择原则:最新/最优:所有测试均基于 2025年11月18日 各平台对外开放的最新商业版本进行。在拥有多个模型版本可选的情况下,默认选择该平台官方推荐的“效果最优”或“旗舰”模型版本。
特殊技术架构说明:Runway 与 Google Veo 的关联:在本次测评版本中,Runway 平台提供多款模型供用户选择,包括 Gen-4、Gen-4 Turbo、Veo 3 及 Veo 3.1。值得注意的是,在文生视频功能中,Runway 仅支持调用 Veo 系列模型,而其自研的 Gen-4 系列则专用于图生视频及视频编辑功能。
(测评影响预判: 这意味着在“文生视频”环节,Runway 与 Google Veo 的生成逻辑可能存在同源性。但在“图生视频”及“视频编辑”功能上,Runway 仍采用其自研技术栈。读者在阅读后续数据时,请留意这一技术背景。)
Google Veo 模式设定:Fast 模式:针对 Google Veo 工具,本次测评统一采用 Fast 模式 进行生成。
(设定理由: 尽管 Veo 拥有更高精度的 Pro 模式,但考虑到 Fast 模式在生成速度与成本上的平衡性更接近商业落地的实际需求,且与其他竞品(通常为标准速度)更具可比性,故作此设定。)
第3章 测评方法论
为了确保测评结果的客观性、可复现性及商业参考价值,本报告构建了一套涵盖“基础能力、经济效率、内容质量”的三维评价体系,并制定了严格的数据清洗与计算标准。
3.1 测试用例设计
本次测评共设计了 17 个行业代表性提示词(Prompts),旨在模拟真实商业环境下的高频需求。
样本构成与来源:
官方复现组 (15个): 选取各工具官方 Showcase 中的高难度案例。
真实业务组 (2个): 由公司市场部员工提供的实际生产需求
覆盖场景: 全面覆盖 文生视频 、图生视频及AI视频编辑三大核心功能区。
语言环境压力测试:
所有测试用例统一使用中文提示词进行输入。
设定逻辑: 鉴于本报告主要面向中国用户,必须测试各工具(尤其是海外工具)在中文语境下的理解与执行能力。
3.2 评价维度体系
本报告采用 “客观数据硬指标 + 主观感官软指标” 相结合的双模评价体系:
3.2.1 基础能力 (客观指标)
3.2.1.1 场景覆盖率
定义:指测试工具在全部 17 个标准测试用例中,能够成功生成有效视频结果的比例。
计算公式:
判定标准: 只要工具产出了视频结果,即视为“覆盖成功”。若因功能缺失(如某工具不支持图生视频)、合规拦截(敏感词风控)或技术报错导致无法产出视频,均计为“未覆盖”。
意义: 该指标反映了工具的适用广度与交付稳定性,即解决“能不能做”的问题。
3.2.1.2 语义符合度
测评人员针对不同用例维度(如动作、光影、主体)进行专项判定。
评分标准:
2分 (高度匹配): 准确还原提示词中的核心要素与细节。
1分 (基本匹配): 核心要素存在,但细节丢失或存在轻微幻觉。
0分 (严重偏离): 生成内容与提示词无关,或出现严重逻辑崩坏。
3.2.2 经济与效率指标 (客观指标)
3.2.2.1 成本核算
单位:人民币 (CNY)。
计算逻辑: 仅计算成功样本。若同一用例尝试了多种模型版本,取所用的最贵模型费用进行核算。若同一模型多次尝试,仅计算单次生成费用(反映标准定价)。
3.2.2.2 时间核算
单位:秒 (s)。
计算逻辑: 仅统计成功生成的耗时。若同一用例有多次成功记录,取其算术平均值。
3.2.3 内容质量(主观·MOS体系)
标准:基于国际电信联盟 ITU-T P.910 视频质量主观评价标准。
样本:10人盲测小组(隐去工具名称,仅看视频内容)。
评分维度与细分指标(8项):
注:“音画同步”中声音包含语音、配乐或音效等各种音频。
3.2.4 数据分析与综合评分模型
为了更直观地对比各工具的综合实力,本报告构建了以下两个衍生分析模型:
3.2.4.1 单位有效画质成本
用于衡量“性价比”
计算公式:
阈值设定: 仅针对 MOS 总分 > 3.5(及格线)的工具进行核算,低于此分数视为无商业价值。
3.2.4.2 五维综合加权评分模型
采用 Min-Max 归一化方法将各维度数据标准化为 0-100 分,并按以下权重加权得出总分:
视频生成质量 (MOS):权重 50%(核心交付标准)
语义理解能力:权重 20%(可控性标准)
经济成本:权重 15%(商业门槛,负向指标)
生成效率:权重 10%(时间成本,负向指标)
场景覆盖率:权重 5%(鲁棒性标准)
3.3 数据处理标准与局限性说明
为确保测评的科学性与公平性,针对数据缺失及计费差异,执行以下标准化处理:
3.3.1 评分计算:有效样本独立均分法
鉴于各工具成功率(场景覆盖率)差异较大,为最大化利用测试数据:
计算规则: 各工具的 MOS 质量分,仅基于其自身成功生成的视频样本计算平均值。(分母 = 该工具成功生成的数量,而非 17)。
解读原则 (关键):
MOS 分值代表“生成质量”(做得好不好)。
场景覆盖率代表“能力边界”(能做多少事)。
风险警示: 需结合两者判断,避免因工具无法生成高难度用例(直接失败不计分)而导致的评分虚高现象(幸存者偏差)。
3.3.2 关键局限性声明
主观评分样本量限制: 本次MOS评分采用10人盲测小组进行,样本量相较于ITU-T P.910标准建议的15人以上存在一定差距。尽管评分流程严格遵循标准化操作,但较小的样本量可能导致个体偏好对结果产生一定影响,读者在参考时应予以考量。
版本时效性: 测试数据基于 2025年11月18日 版本,AI迭代极快,结论仅对该时间点负责。
第4章 横向对比分析
4.1 基础性能对比
4.1.1 场景覆盖率与交付能力
反映工具的“能力边界”与“抗压性”
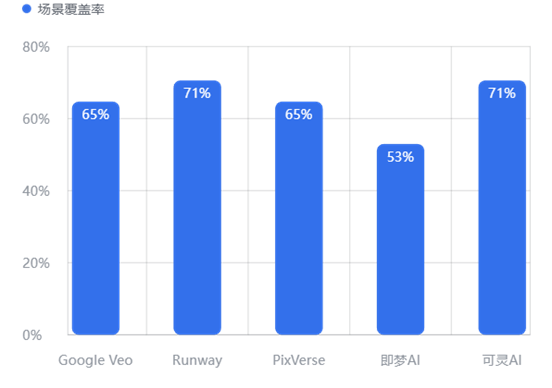
【数据解读】
第一梯队 (Runway, 可灵AI - 0.71): 这两款工具展现了最强的鲁棒性。在面对敏感词回避、复杂逻辑组合等高压测试下,它们拥有最高的成功交付率。这意味着在商业项目中,选用这两款工具“交付失败”的风险最低。
中坚力量 (Google Veo, PixVerse - 0.65): 表现中规中矩,能覆盖绝大多数常规需求,但在特定极端指令下可能出现拒识或生成失败。
短板明显 (即梦AI - 0.53): 仅能完成约一半的测试用例。这表明该工具在应对非标准、高难度提示词时存在明显的能力边界,用户可能需要花费更多精力去“抽卡”或调整指令。
4.1.2 语义理解力
反映工具是否“听得懂人话”,尤其是中文指令。
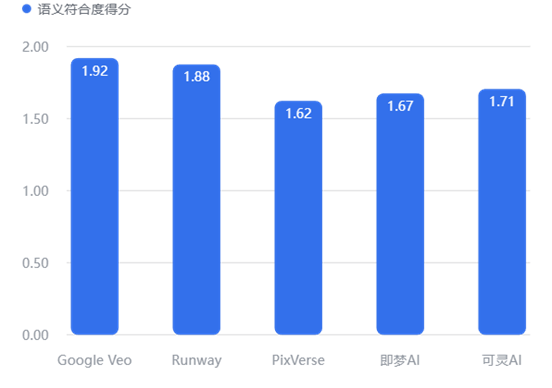
【数据解读】
Google Veo (1.92) 意外登顶: 尽管作为国际模型,Veo 在中文语境下的语义对齐能力令人惊叹,几乎完美还原了提示词中的主体与环境细节。这可能得益于其底层强大的多模态大模型架构。
Runway (1.88) 紧随其后: 表现出极高的指令遵循度。
PixVerse (1.62) 垫底: 该工具在理解复杂中文长难句时显得吃力,常出现“忽略修饰词”或“主体错乱”的现象,建议用户在使用时尽量简化指令或使用英文。
4.2 经济与效率指标对比
4.2.1 价格成本分析:单次生成成本对比
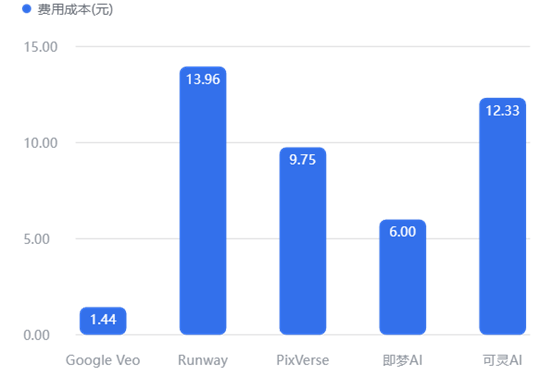
【数据解读】
价格断崖: 市场呈现极端的两极分化。
极具成本优势: Google Veo (1.44元) 凭借 Fast 模式,将视频生成成本压低至行业最低水平,仅为竞品的 1/10。这对高频试错的创作者极具吸引力。
高端定价策略: Runway (13.96元) 与 可灵AI (12.33元) 处于高价区,商业试错门槛极高。
4.2.2 时间效率分析:平均生成耗时对比
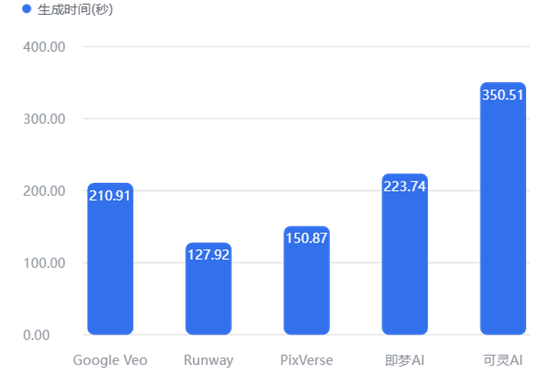
【数据解读】
速度优势显著: Runway (127.92秒) 是唯一进入“2分钟俱乐部”的工具,极大地优化了工作流效率。
耐心考验: 可灵AI (350.51秒) 的平均耗时接近 6 分钟,是 Runway 的近 3 倍。在需要反复修改的商业项目中,这种漫长的等待时间将显著拉低生产力。
4.3 视频质量对比 (MOS)
4.3.1 总分排行榜:MOS平均分总榜
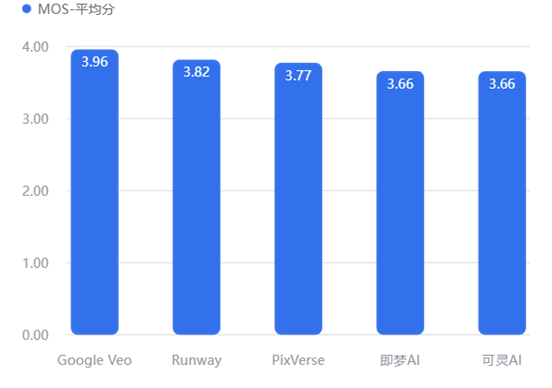
【数据解读】
画质王者: Google Veo (3.96) 以绝对优势领跑,展现了顶尖的的画面统治力。
第二梯队: Runway (3.82) 与 PixVerse (3.77) 咬合紧密,属于优秀可用的范畴。
提升空间: 即梦AI 与 可灵AI 均为 3.66 分,虽然在及格线以上,但在细节质感上与国际头部模型仍有差距。
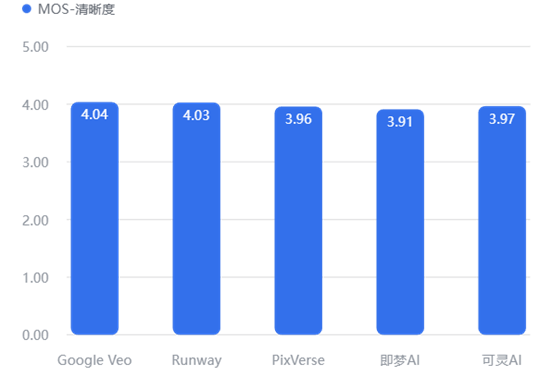
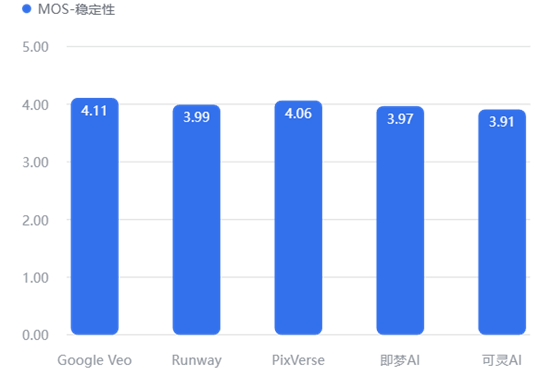
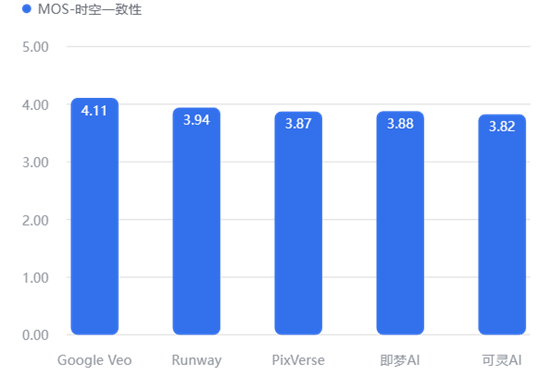
4.3.2 细分维度对比
清晰度
稳定性
时空一致性
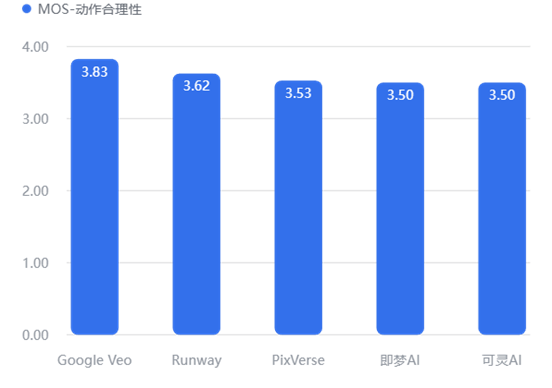
动作合理性
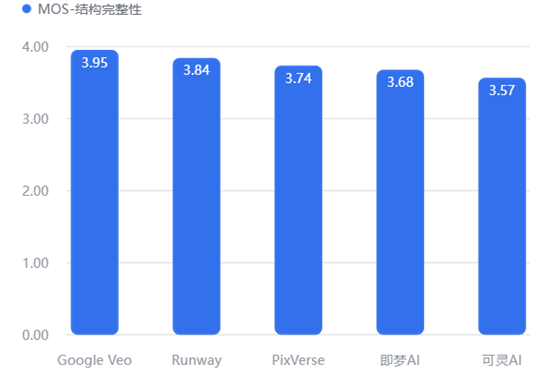
结构完整性
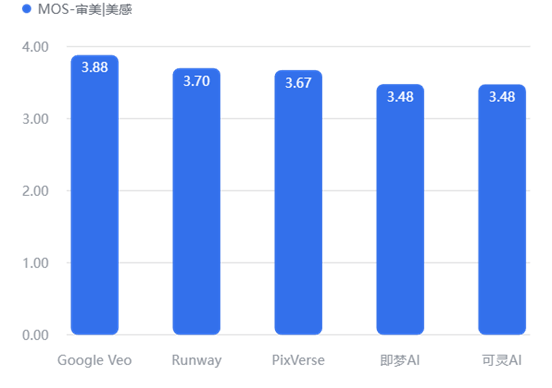
审美/美感
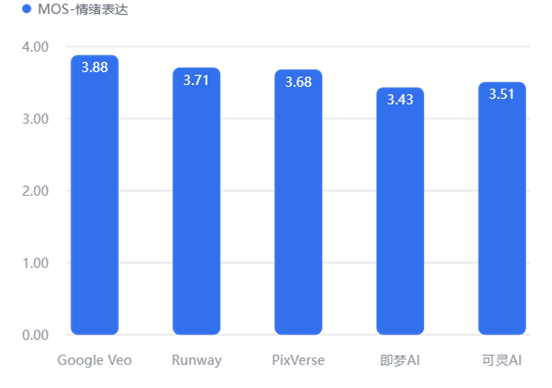
情绪表达
音画同步
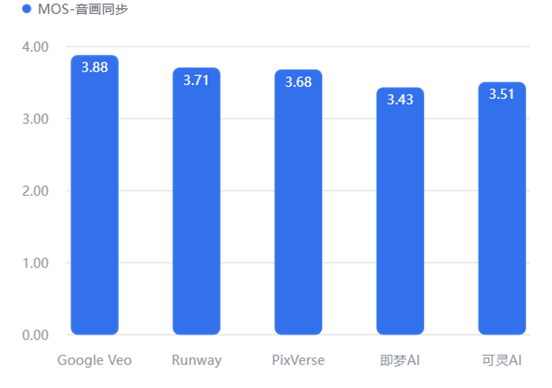
【数据解读】
物理规律(动作/结构/时空)
这是 AI 视频最难攻克的堡垒。Google Veo 在“动作合理性”(3.83) 和“时空一致性”(4.11) 上大幅领先,说明它最懂“物理世界是如何运作的”。
反观 PixVerse 和 可灵AI,在动作合理性上仅得 3.50-3.53 分,生成的视频容易出现“太空步”或“肢体穿模”现象。
视听体验(清晰/稳定/音画)
各家在“清晰度”上差距不大(均在 3.9-4.0 之间),说明高清画质已成行业标配。
但在“音画同步”上,Google Veo (3.88) 再次碾压即梦AI (3.43),证明了其在多模态对齐上的技术壁垒。
艺术表现(审美/情绪)
即梦AI 和 可灵AI 在“审美/美感”上得分较低 (3.48),生成的画面往往带有较重的“AI塑料感”或构图平庸,不如 Veo (3.88) 具有电影质感。
4.3.3 场景适应性
文生视频
图生视频
AI视频编辑
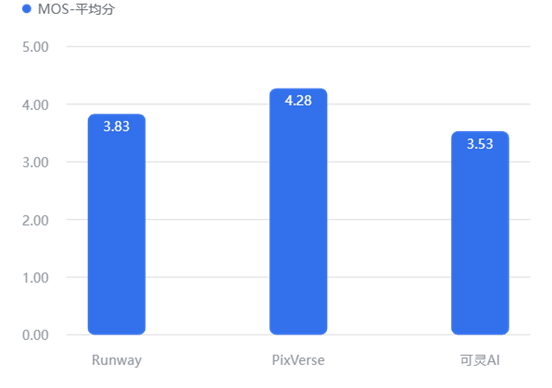
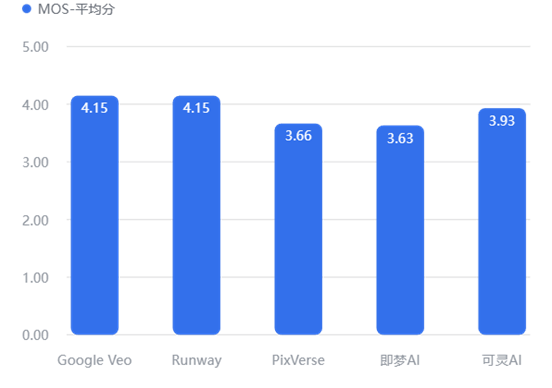
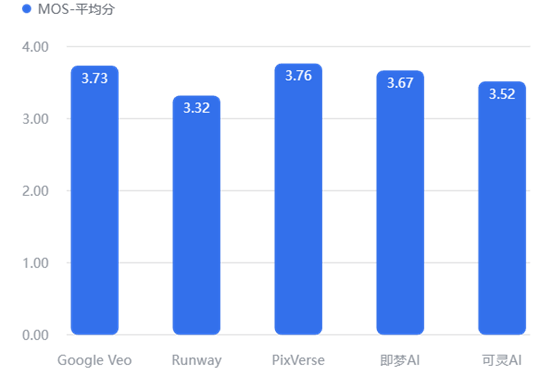
【数据解读】
文生视频 : Google Veo 与 Runway 并列第一 (4.15),是创意起号的最佳选择。
图生视频: 局势反转。PixVerse (3.76) 逆袭夺冠,证明其在保持原图特征方面做得最好。而 Runway (3.32) 在此项遭遇滑铁卢,说明其参考图控制力较弱。
AI视频编辑: PixVerse (4.28) 展现了统治级表现,是目前唯一真正能用于“精准局部重绘”的工具。
4.4 性价比排行榜
4.4.1 统计结果
基于第三章3.2.4.1 节定义的“单位有效画质成本”模型,我们得出了以下排名。该指标数值越低,代表用户获取同等画质所支付的溢价越少。
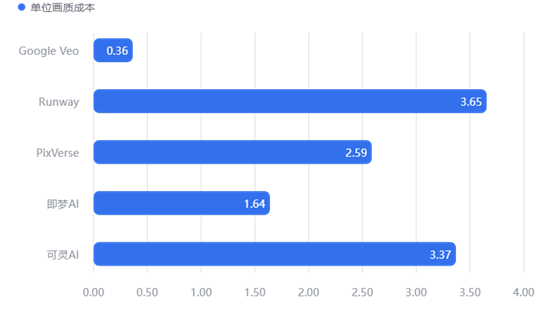
【数据解读】
Google Veo (0.36): 绝对的性价比之神。它用最低的价格提供了最高的画质,是预算有限团队的首选。
PixVerse (2.59) & 即梦AI (1.64): 处于中间地带,定价相对合理。
Runway (3.65) & 可灵AI (3.37): 性价比极低。用户为了获得同等画质,需要支付比 Veo 高出近 10 倍的溢价。除非它们拥有某些不可替代的独家功能,否则在纯画质采购上不具备竞争力。
4.5 综合加权排行榜
4.5.1 评分结果
依据第三章 3.2.4.2 节设定的“五维综合加权评分模型”,各工具的最终得分如下:
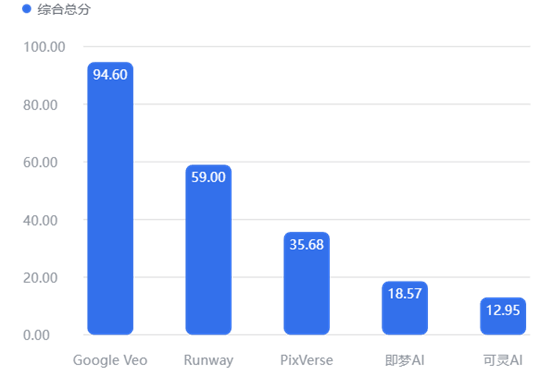
4.5.2 榜单深度解读
Google Veo 的统治力: 94.6 的高分源于它在“质量”和“成本”两个最大权重项上的绝对优势。它重新定义了 2025 年视频生成的标准——不仅要好,还要便宜。
Runway 的尴尬: 尽管覆盖率和速度表现优异,但过高的定价(成本项得分极低)严重拖累了其综合排名。它依然是专业人士的利器,但不再是普适的首选。
可灵 AI 的排名陷阱: 尽管可灵在“场景覆盖率”上与 Runway 并列第一(说明它功能很全),但由于其生成速度最慢且价格第二贵,加之 MOS 质量分仅处于平均水平,导致其在综合加权算法下排名垫底。这提示可灵团队需急需解决算力效率与定价策略问题。
第5章 各工具详细测评结果
本章节基于“归一化”后的五维评分模型,为每一款工具绘制了能力画像。请注意,得分为相对值(0-100),反映了该工具在本次横向测评中的相对位置,100分代表该维度表现最佳,0分代表该维度表现相对最弱。
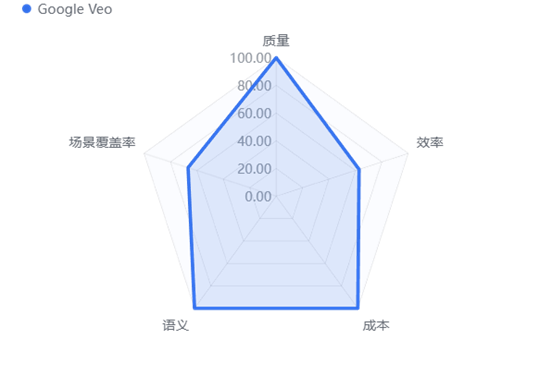
5.1 Google Veo
5.1.1 综合画像
“2025年度全能王者”。Google Veo 以压倒性的优势占据榜首。它不仅在视频生成的物理规律模拟和画质精细度上代表了行业天花板,更通过 Fast 模式将成本压低至竞品的十分之一,实现了高端画质与平价成本的平衡。
5.1.2 五维能力雷达图
5.1.3 核心优势
极致性价比: 在质量(MOS 3.96)和成本(1.44元/次)两个核心维度上均获得满分(100分)。它是目前市场上唯一能同时提供电影级画质和极低试错成本的工具。
物理世界模拟大师: 在“动作合理性”和“时空一致性”上遥遥领先,能够精准还原流体、光影及复杂物理运动,极少出现反物理的“幻觉”。
中文语义理解惊人: 尽管是国际模型,但在中文复杂指令的理解上得分最高(1.92分),对提示词的还原度极高。
5.1.4 劣势与局限
访问门槛: 作为 Google DeepMind 旗下产品,国内用户访问及使用需要特定的网络环境配置。
覆盖能力不足:场景覆盖率仅为65%,在5款工具中排名第4,低于Runway和可灵AI的71%。这意味着在17个测试用例中,有约6个无法成功生成视频。对于需要处理多样化场景的商业项目,Veo的适用性存在明显局限。
5.2 Runway
5.2.1 综合画像
“高成本、高效率的专业级工具”。Runway 依然是行业内速度最快、稳定性最强的工具。
5.2.2 五维能力雷达图

5.2.3 核心优势
速度优势显著: 平均耗时仅 127.92 秒,效率得分满分(100分),是追求高周转率的商业项目的首选。
交付极其稳定: 场景覆盖率满分(100分),无论是敏感词规避还是复杂逻辑,Runway 都能稳定产出结果。
文生视频强劲: 得益于接入 Veo 底层,其文生视频质量极高,语义理解力(86.67分)紧随 Google Veo之后。
5.2.4 劣势与局限
价格劝退: 成本得分归零(0分),单次生成高达 13.96 元。对于个人创作者而言,每一次点击“Generate”都需要深思熟虑。
图生视频短板: 在图生视频环节表现不如 PixVerse,参考图控制力相对较弱,容易丢失原图特征。
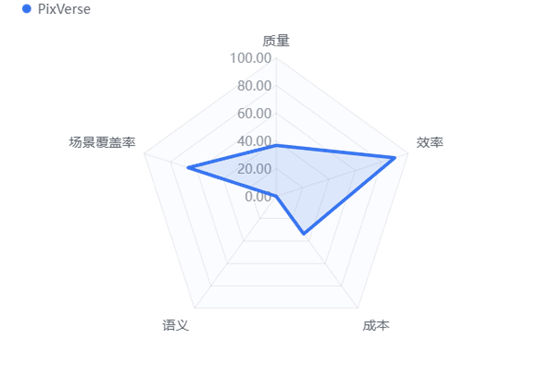
5.3 PixVerse
5.3.1 综合画像
“偏科的后期专家”。PixVerse 是一匹特色鲜明的黑马。虽然它在听懂复杂指令方面表现糟糕,但在“修图”和“动图”(图生视频、视频编辑)领域展现了统治级的实力,适合有明确底图素材的创作者。
5.3.2 五维能力雷达图
5.3.3 核心优势
编辑与图生视频之王: 在文生视频(3.76分)和 AI视频编辑(4.28分)细分榜单中夺冠。它能完美保留原图人物特征,并进行精准的局部重绘。
生成效率优秀: 效率得分 89.69,生成速度仅次于 Runway,用户体验流畅。
5.3.4 劣势与局限
语义理解灾难: 语义得分归零(0分)。在面对复杂的中文长难句时,经常忽略修饰词或搞错主体,强烈建议搭配英文提示词使用。
物理规律弱项: 动作合理性评分较低,生成的人物动态容易出现僵硬或滑步现象。
5.4 即梦AI
5.4.1 综合画像:
“入门级的美学尝鲜者”。即梦 AI 背靠字节跳动,拥有不错的底子,但在此次高压测评中表现出明显的“偏科”和“体能不足”。它适合低预算用户进行简单的短视频素材生成,但在应对复杂商业需求时显得力不从心。
5.4.2 五维能力雷达图

5.4.3 核心优势
价格适中: 成本得分 63.58,处于市场中游水平,比 Runway 和可灵更亲民,适合预算有限的个人用户。
构图美学基础: 虽然总分不高,但在静态画面的构图和色彩上继承了字节系产品的优势,适合生成意境类空镜。
5.4.4 劣势与局限
交付能力堪忧: 覆盖率得分归零(0分),仅能完成约 53% 的测试用例。面对高难度提示词,它经常无法生成有效视频。
质感塑料化: 质量得分归零(MOS均分垫底),生成的视频往往带有较重的“AI滤镜感”,缺乏电影级的真实纹理。
5.5 可灵AI
5.5.1 综合画像
“功能全面但效率受限的综合型工具”。可灵 AI 是国产模型中的“鲁棒性最强的工具”,拥有和 Runway 一样强大的场景覆盖能力和中文适配性。然而,极其缓慢的生成速度和高昂的定价,使其成为了一个“好用但难用”的矛盾体。
5.5.2 五维能力雷达图:
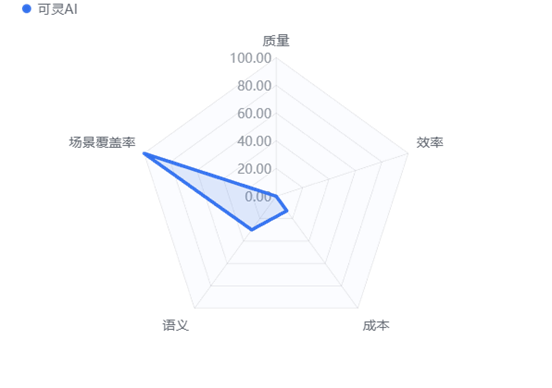
5.5.3 核心优势
鲁棒性极强: 覆盖率得分满分(100分)。作为国产模型,它最懂中国用户的表达习惯,且风控逻辑与生成能力平衡得当,几乎什么都能做。
本土化体验: 全中文界面与原生中文语义支持,对于不熟悉英文提示词的国内用户最为友好。
5.5.4 劣势与局限
效率瓶颈: 效率得分归零(0分)。平均近 6 分钟的生成时间(350秒+)严重阻碍了创作心流,商业交付效率极低。
性价比陷阱: 成本得分极低(13.02分),单次生成成本(12.33元)紧逼 Runway,但画质(MOS 3.66)却处于第二梯队末端,导致其“单位画质成本”极高,不划算。
第6章 风险警示与避坑指南
本章节汇总了测试团队在数百次生成过程中遇到的实际痛点与隐形风险。这些内容通常不会出现在官方宣传页中,但却是决定项目能否顺利交付的关键。
6.1 风险警示录
6.1.1 合规、网络与风控
Google Veo 的“围墙”与“洁癖”
访问门槛: 中国大陆地区仍不在官方支持范围内,国内用户访问需借助特定网络环境配置。
过度风控: 安全策略极为严格,诸如“小女孩”等普通词汇极易触发禁词拦截。
字幕乱码: 尽管其对中文提示词理解极佳,但若要求在视频画面内生成中文字幕或招牌,极大概率会出现乱码。
功能阉割: Flow 平台不支持上传用户本地视频,这意味着无法对已有视频进行扩展(Outpainting)或修改。
PixVerse 的“语言隔阂”:
中文拒识: 尽管宣称支持中文,但在输入中文提示词(尤其是接近950汉字上限)时,系统理解能力极差(语义分0分),强烈建议全程使用英文提示词。
可灵 AI 的内容风险:
合规双刃剑: 测试中发现偶有擦边球视频生成,企业用户需警惕品牌安全风险。此外,视频中存在物品突然消失或声音错误的“幻觉”现象。
6.1.2 计费陷阱
Runway 的“失败扣费”机制:
重要提示: 即使创建失败(报错或无结果),系统依然会扣除积分。
Veo 模型溢价: 在 Runway 中调用 Google Veo 模型(文生视频)时,单次消耗高达 3 美元(约 21元人民币),且积分消耗无明显弹窗提示,极易造成预算瞬间耗尽。
订阅坑: 包月积分仅发放一次,耗尽后需额外购买昂贵的加油包,且菜单逻辑混乱,难以监控消耗。
可灵 AI 的“贵族”定价:
部分高阶模型生成 10秒视频需消耗约 10元人民币,且存在排队时间过长(高峰期达14分钟)的问题,试错成本极高。
6.1.3 功能缺陷与体验痛点
即梦 AI 的“半成品”交付:
后期工作量大: 生成的视频默认为无声,且帧率较低(需手动补帧至60fps)。
配音限制: 手工补对话仅支持单人声音,无法实现多角色对话。
编辑限制: 不支持对视频进行扩展、添加或删除对象。
进度条欺诈: 生成进度条严重不准,不可作为预估时间的依据。
PixVerse 的逻辑崩坏:
突变现象: 视频中常出现人物动作突变、物品凭空出现等不符合逻辑的画面。
播放延迟: 视频生成后,服务器端常需缓冲一段时间才能正常播放。
第7章 商业分析与市场洞察
7.1 商业模式解析:从“SaaS”到“MaaS”的算力博弈
2025 年的 AI 视频生成市场,正在经历一场由算力成本决定的定价模式重塑。与传统的软件订阅(SaaS)不同,视频生成的高昂算力消耗使得“模型即服务”(MaaS)的特征更为显著。
7.1.1 “抽卡机制”与隐形税
现象: 测评中 Runway 和可灵 AI 的高昂成本(~13元/次)与其“积分制”设计密切相关。用户不仅在为成功的视频付费,更在为大量失败的废片(幻觉、崩坏、拒识)买单。
痛点分析: 正如测试反馈所示,Runway 甚至在生成失败时也会扣除积分。这种机制类似于游戏中的“抽卡”,将模型不确定性的风险转嫁给了用户。
结论: 在模型良品率达到 90% 之前,单纯的“积分制”对专业用户极不友好。未来,“按结果付费”或“失败退币”机制将成为厂商争夺用户的关键差异化服务。
7.1.2 定价两极化背后的“算力鸿沟”
为何 Google Veo 能做到 1.44元/次的“白菜价”,而可灵 AI 和 Runway 却居高不下?这反映了中美 AI 基础设施的底层差异:
国际巨头的降维打击(Google):
Google 拥有自研的 TPU(张量处理单元)集群和完整的云生态。Veo 的低价策略本质上是“基础设施复用”带来的边际成本递减。Google 意不在卖视频生成,而在通过 Veo 将用户锁定在其 Gemini 和 Workspace 生态中。
创业公司与本土模型的困境(Runway / 可灵):
算力赤字: 中国本土模型(如可灵)受限于高性能 GPU(如 H100/H800)的获取难度,推理成本天然较高。测试中可灵“排队 14 分钟”的现象,正是算力供给不足的直接体现。
生存压力: Runway 等创业公司必须通过高定价来覆盖昂贵的第三方云算力租用成本(通常租用 AWS 或 Azure),无法像 Google 那样进行交叉补贴。
7.1.3 订阅制 vs. 积分制的选型逻辑
高频低质(社交媒体/玩梗): 适合订阅制(如即梦 AI),通过包月获得大量低精度生成额度,容忍度高。
低频高质(影视/广告): 适合按量付费,虽然单价贵,但配合“高良品率”模型(如 Veo),总成本反而可控。
7.2 技术趋势预测 (2025-2026)
基于本次测评中各工具的优劣势(如 PixVerse 的编辑强、Veo 的物理强),我们预判未来 12-18 个月技术将向以下三个方向演进:
7.2.1 从“盲盒生成”到“精准控制”
现状: 目前大多数工具(如即梦、Runway)仍停留在“抽奖”阶段,用户难以控制人物的具体动作幅度或运镜轨迹。
趋势: 后处理功能将成为标配。
局部重绘: 像 PixVerse 那样允许用户圈选特定区域(如只修改手部动作,保持脸部不变)将成为行业标准。
摄像机控制: 用户将能通过简单的 3D 运镜参数(Pan, Tilt, Zoom)来约束 AI 的生成,而非仅靠文字描述。
7.2.2 “默片时代”的终结
现状: 即梦 AI 生成视频无声、可灵 AI 声音错误、Runway 需单独配音。这使得目前的 AI 视频仅是“半成品”。
趋势: 原生音画同步将爆发。
Google Veo 已经展示了端倪,未来的模型将是 Video+Audio Token 混合训练。生成的视频将自带符合物理环境的音效(如脚步声随距离变化)和口型对齐的对白,彻底省去人工后期配音的环节。
7.2.3 语义理解的“去提示词化”
现状: 用户需要学习复杂的“咒语”(Prompt Engineering),且如 PixVerse 等工具对中文支持极差。
趋势: 多模态意图识别。
未来的工具将更多依赖“参考图+简单指令”而非长篇大论的文字。模型将具备更强的常识推理能力(如输入“悲伤的雨天”,AI 自动添加冷色调滤镜和雨声,无需用户显式描写光影细节)。
7.2.4 市场格局判断
寡头化风险: 随着 Google Veo 等巨头入场,单纯做“文生视频模型”的创业公司(如 Runway)生存空间将被挤压。它们必须转型为“专业工作流工具”(提供强大的编辑、抠像、调色功能),否则将被巨头的低价策略吞噬。
本土化机遇: 尽管算力受限,但可灵 AI 等国产工具在“中文语境理解”和“中国特色内容”(古风、短剧逻辑)上拥有不可替代的护城河。国内市场将形成“应用层繁荣”与“底层算力紧缺”并存的独特生态。
第8章 结论与建议
8.1 测评结语:从"多元竞争"到"梯队分化"
2025 年的 AI 视频生成领域并未如预期般实现“众生平等”,反而呈现出明显的技术与体验分层。
技术天花板: Google Veo 凭借深厚的算力储备和多模态架构,确立了画质与物理规律的绝对标杆,同时将成本压低至竞品的 1/10,对行业构成了降维打击。
商业化壁垒: Runway 虽然在画质上被追赶,但凭借极高的生成速度和稳定性,依然守住了专业商业交付的护城河。
本土化困境与突围: 可灵 AI 和 即梦 AI 在中文语境和本土审美上具有天然优势,但受限于算力成本,面临着“排队久、定价高、功能半成品(如无声)”的严峻挑战。
细分赛道黑马: PixVerse 证明了通用模型之外,专注于“图生视频”和“局部编辑”的垂直工具依然具有不可替代的生态位。
8.2 核心推荐榜单
基于“质量、成本、效率、语义一致性、覆盖率”的综合考量,本报告给出以下最终评级:
年度最佳画质奖 (Quality King): Google Veo
理由: 拥有最接近电影级的物理模拟能力和光影质感,且 Fast 模式性价比极高。
最佳商业交付奖 (Efficiency Leader): Runway
理由: 唯快不破。在时间紧迫的商业项目中,它是唯一能保证“按时交片”且不崩坏的工具。
最佳中文适配奖 (Best Localization): 可灵 AI (Kling)
理由: 最懂中国话,最懂中国风。在国内短剧和电商场景下,其语义理解力无人能及。
最佳后期编辑奖 (Best Editing): PixVerse
理由: 它是目前唯一真正可用的“视频修图师”,在保持原图特征和局部重绘上表现卓越。
8.3 分层选型建议
为了最大化您的投入产出比(ROI),建议根据具体业务场景对号入座:
场景 A:专业影视预演 / 广告 TVC / 追求极致视觉
推荐组合: Google Veo (主力生成) + PixVerse (局部修补)
策略: 利用 Veo 的低成本和高画质进行大量“抽卡”以获取最佳底片,再导入 PixVerse 进行细节微调。
避坑: 需解决 Veo 的网络访问问题,并全程使用英文提示词。
场景 B:短视频营销 / 电商素材 / 赶截止日期
推荐组合: Runway (主力) + 剪映 (后期)
策略: 预算换时间。利用 Runway 的极速生成能力快速产出素材,虽然单价贵,但能确保项目不延期。
避坑: 严格检查提示词,避免因失败扣费导致预算超支。
场景 C:国内短剧制作 / 古风内容 / 中文脚本
推荐组合: 可灵 AI (主力) + 即梦 AI (辅助空镜)
策略: 利用可灵 AI 精准还原复杂的中文剧本描述。对于要求不高的空镜或唯美过场,可用成本较低的即梦 AI 替代。
避坑: 务必预留 1-2 小时的“排队缓冲期”,切勿在交片前一刻才开始生成。
场景 D:二次元创作 / 静态插画动效化
推荐组合: PixVerse (独占)
策略: 只有 PixVerse 能在让纸片人“动起来”的同时不崩坏脸部特征。
避坑: 必须使用英文提示词,且需多尝试几次以规避逻辑突变。
8.4 最终建议
2025 年是 AI 视频生成的“祛魅之年”。测评表明,没有任何一款工具是完美的“全能型工具”。
给个人的建议: 不要迷信单一工具。建立“组合式工作流”(例如:用 Veo 生成画面,用可灵生成中文特有元素,用 PixVerse 修复瑕疵,最后人工配音)是目前达到商业可用标准的唯一路径。
给企业的建议: 警惕算力成本陷阱。在采购前,务必进行小规模的“良品率测试”。对于高频需求,购买算力资源(如部署开源模型或 API 接入)可能比订阅 SaaS 平台更具性价比。